Cost-effective tracing with sampling
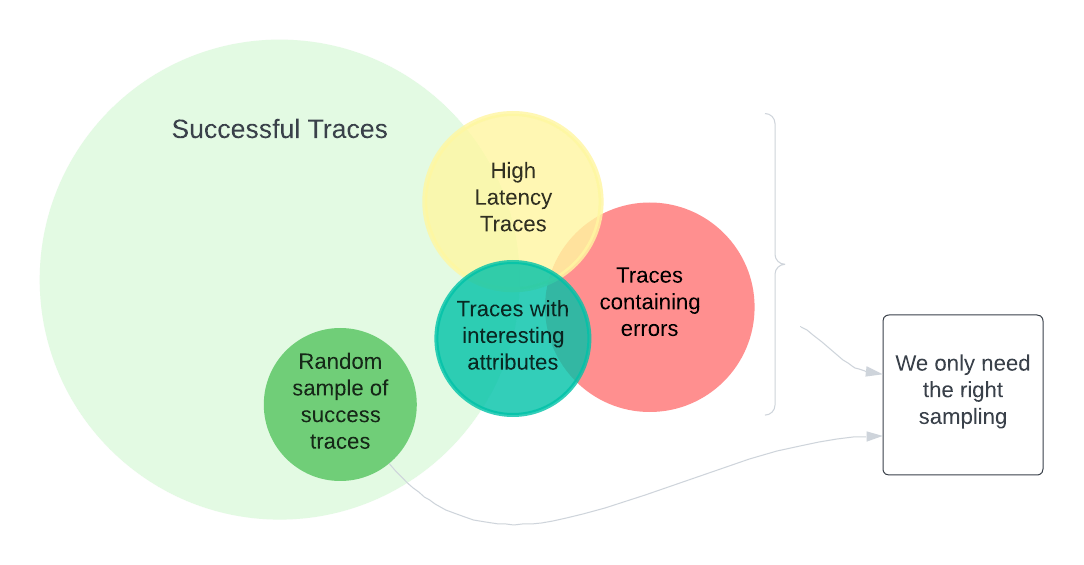
While traces are extremely useful, in a standard application most of the traces are not very interesting, especially when they represent a successful execution - usually, we’re more interested in the traces that are out of the ordinary, or represent errors or slow operations.
It doesn’t mean that we don’t store traces that represent success, but we might want to store fewer of them, just enough where we can still look at patterns and extract metrics and other useful information.
Why do we need sampling?
When using traces at scale, the amount of data generated can be overwhelming and, at the same time, costly to store and process. Sampling is a technique that allows us to reduce the amount of data collected, while still providing a representative view of the system.
It’s not always trivial to choose the right sampling strategy, as it depends on the use case and the type of data we want to collect. In general, we can distinguish between two main categories of sampling: head-based and tail-based.
Head-based sampling
The first type of sampling is called head-based sampling and the goal is to make a decision as early as possible, so it doesn’t take into account the whole trace. The most common implementation of this strategy is to sample a fixed percentage of traces.
On the one hand, this type of sampling is very efficient and can be implemented with very little overhead, but on the other hand, it’s not very flexible and it’s not very useful when we want to sample based on the characteristics of the trace. If we want to sample based on the attributes of the whole Trace, like the duration or errors, we need tail-based sampling.
Tail-based sampling
The other type of sampling is tail-based sampling, and it happens after the full set of spans have been completed. This means that we can use the attributes of the Trace to decide if we want to sample it or not.
We can use this type of sampling to do things to collect Traces that:
- are longer than a certain threshold
- contain errors
- contain specific attributes
And also change the sampling rate based on these rules (e.g. sample 100% of traces that contain errors, but only 10% of traces that are longer than 5 seconds).
However, we must be aware of some of the drawbacks of tail-based sampling:
- more expensive, as we need to collect the full Trace before we can make a decision
- more difficult to implement, and may require changes when the applications evolve
- depending on the implementation/infrastructure it may require special care when scaling intermediaries like OpenTelemetry Collector
The problem of sampling in a Distributed Tracing system
While we can use head-based and tail-based sampling in a single application, it’s not as straightforward when we’re dealing with a distributed system. In this case, we need to make sure that we’re sampling consistently across all the services involved in a single trace, otherwise, we’ll end up with incomplete Traces that are not very useful.
What we need is a way to decide if a Trace should be sampled or not, and make sure every service involved in the Trace makes the same decision. We can use context propagation to signal downstream services that a Trace should be sampled, and then configure each service to look at the context first to decide if a Trace should be sampled or not.
This is called Parent-based sampling - in Distributed Tracing, to ensure consistency, before applying any sampling strategy, we first check if the parent Trace was sampled or not, and then apply the same decision to the current Trace.
It doesn’t mean that some service in the middle of a call chain can’t create more Traces than the parent, but it means that the parent’s decision is always respected. There are still situations where we might want to sample a Trace when we detect odd behavior - we won’t have a complete call chain, but we’ll still have a Trace that can help us understand what’s going on.
Real-world examples
In most scenarios, we want to use a combination of head-based and tail-based sampling. It can be implemented in layers, and we can use different sampling strategies at each layer. For example, we can use Parent-based sampling at the first layer, then allow for 100% sampling of traces that are longer than 5 seconds or contain errors.
We can restrict or control the amount of data flowing through the telemetry infrastructure by using head-based sampling (e.g. probability sampling) on the first nodes of a call chain (the others would use parent-based sampling).
Then, we can use tail-based sampling to further reduce the amount of data we collect, and make more informed decisions based on the characteristics of the Trace.
Implementing a custom Sampler with the OpenTelemetry SDK
The OpenTelemetry SDK provides a Sampler interface that we can implement to create our own custom Samplers. The interface is very simple, and it only requires us to implement a single method called shouldSample that takes a bunch of parameters and returns a SamplingResult object. There is technically one more method called getDescription but usually, you’ll only need to return the name of your sampler here.
public class AllErrorsSampler implements Sampler {
@Override
public SamplingResult shouldSample(
Context parentContext,
String traceId,
String name,
SpanKind spanKind,
Attributes attributes,
List<LinkData> parentLinks
) {
return SamplingResult.create(SamplingDecision.RECORD_AND_SAMPLE);
}
@Override
public String getDescription() {
return "AllErrorsSampler";
}
}
You may notice that this interface could be used to implement either head-based or tail-based sampling but unless you are tracing a single service, most of the time this won’t work for tail-based sampling.
While you can look at the service spans and their attributes to decide if you want to sample a Trace or not, you can’t look at the spans of the other services involved in the Trace. Also, if you detect an error in a downstream service call, you can’t change the sampling decision retroactively for that, since the context was already propagated without that information.
This essentially means that you can only implement tail-based sampling correctly for a distributed system if you have access to the full Trace, which in turn means that you need to implement it in the OpenTelemetry Collector - making sure every single Span is received by the same Collector instance. We’ll get into more detail about the OpenTelemetry Collector deployment strategies in a future post.
Using OpenTelemetry Collector for sampling
The OpenTelemetry Collector provides a lot of flexibility when it comes to sampling. It supports head-based sampling out of the box, and it also provides a way to implement tail-based sampling using the Tail Sampling Processor.
This article is not about the OpenTelemetry Collector, so we won’t go into too much detail here, but we’ll see how we can configure it to implement a simple tail-based sampling strategy.
For example, if we want to sample all traces longer than 5 seconds, we can use the following configuration:
processors:
tail_sampling:
decision_wait: 10s # Wait time since the first span of a trace before making a sampling decision, default = 30s
num_traces: 1000 # Number of traces kept in memory, default = 50000
policies:
[
{
name: sample-long-trace-policy,
type: latency,
latency: {threshold_ms: 5000}
}
]
As mentioned before, you need to keep in mind that every single Span for the same Trace must be handled by the same Collector instance, otherwise, the sampling decision will be inconsistent. We’ll see how to do that in a future post.
References
https://opentelemetry.io/docs/concepts/sampling/